Linux命令文件操作
3. 文件操作¶
3.1 cat¶
cat 命令用于连接文件并打印到标准输出设备上。
cat [-AbeEnstTuv] [--help] [--version] fileName
参数说明
- -n 或 --number:由 1 开始对所有输出的行数编号
- -b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
- -s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
- -v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
- -E 或 --show-ends : 在每行结束处显示 $。
- -T 或 --show-tabs: 将 TAB 字符显示为 ^I。
- -A, --show-all:等价于 -vET。
- -e:等价于"-vE"选项;
- -t:等价于"-vT"选项;
[root@cmz cmz]# cat -n hosts
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3
4
5 192.168.186.139 k8s-master01
6 192.168.186.141 k8s-node01
7 192.168.186.142 k8s-node02
---------------------------------------------
[root@cmz cmz]# cat -b hosts
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3 192.168.186.139 k8s-master01
4 192.168.186.141 k8s-node01
5 192.168.186.142 k8s-node02
---------------------------------------------
[root@cmz cmz]# cat -s hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.186.139 k8s-master01
192.168.186.141 k8s-node01
192.168.186.142 k8s-node02
[root@cmz cmz]# cat -sn hosts
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3
4 192.168.186.139 k8s-master01
5 192.168.186.141 k8s-node01
6 192.168.186.142 k8s-node02
---------------------------------------------
[root@cmz cmz]# cat -E hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4$
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6$
$
$
192.168.186.139 k8s-master01 $
192.168.186.141 k8s-node01$
192.168.186.142 k8s-node02$
---------------------------------------------
[root@cmz cmz]# cat -T hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.186.139 k8s-master01
192.168.186.141 k8s-node01
192.168.186.142 k8s-node02
^I
3.2 tac¶
倒着输出所有内容
[root@cmz cmz]# tac hosts 192.168.186.142 k8s-node02 192.168.186.141 k8s-node01 192.168.186.139 k8s-master01 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
3.3 more¶
Linux more 命令类似 cat ,不过会以一页一页的形式显示,更方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能(与 vi 相似),使用中的说明文件,请按 h 。
more [-dlfpcsu] [-num] [+/pattern] [+linenum] [fileNames..]
参数:
- -num 一次显示的行数
- -d 提示使用者,在画面下方显示 [Press space to continue, 'q' to quit.] ,如果使用者按错键,则会显示 [Press 'h' for instructions.] 而不是 '哔' 声
- -l 取消遇见特殊字元 ^L(送纸字元)时会暂停的功能
- -f 计算行数时,以实际上的行数,而非自动换行过后的行数(有些单行字数太长的会被扩展为两行或两行以上)
- -p 不以卷动的方式显示每一页,而是先清除萤幕后再显示内容
- -c 跟 -p 相似,不同的是先显示内容再清除其他旧资料
- -s 当遇到有连续两行以上的空白行,就代换为一行的空白行
- -u 不显示下引号 (根据环境变数 TERM 指定的 terminal 而有所不同)
- +/pattern 在每个文档显示前搜寻该字串(pattern),然后从该字串之后开始显示
- +num 从第 num 行开始显示
-
fileNames 欲显示内容的文档,可为复数个数
-
Enter 向下n行,需要定义。默认为1行
- Ctrl+F 向下滚动一屏
- 空格键 向下滚动一屏
- Ctrl+B 返回上一屏
- = 输出当前行的行号
- :f 输出文件名和当前行的行号
- V 调用vi编辑器
- !命令 调用Shell,并执行命令
- q 退出more
[root@master01 tmp]# more hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3.4 less¶
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
less [参数] 文件
参数说明:
- -b <缓冲区大小> 设置缓冲区的大小
- -e 当文件显示结束后,自动离开
- -f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
- -g 只标志最后搜索的关键词
- -i 忽略搜索时的大小写
- -m 显示类似more命令的百分比
- -N 显示每行的行号
- -o <文件名> 将less 输出的内容在指定文件中保存起来
- -Q 不使用警告音
- -s 显示连续空行为一行
- -S 行过长时间将超出部分舍弃
- -x <数字> 将"tab"键显示为规定的数字空格
- /字符串:向下搜索"字符串"的功能
- ?字符串:向上搜索"字符串"的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- b 向后翻一页
- d 向后翻半页
- h 显示帮助界面
- Q 退出less 命令
- u 向前滚动半页
- y 向前滚动一行
- 空格键 滚动一页
- 回车键 滚动一行
- [pagedown]: 向下翻动一页
- [pageup]: 向上翻动一页
[root@master01 ~]# history | less
1 yum install
2 yum install net-tools
3 sed -i 's@SELINUX=enforcing@SELINUX=disabled@g' /etc/selinux/config
4 setenforce 0
5 systemctl disable firewalld # 开机不自启防火墙
1 yum install
3.5 head¶
head 与 tail 就像它的名字一样的浅显易懂,它是用来显示开头或结尾某个数量的文字区块,head 用来显示档案的开头至标准输出中,而 tail 想当然尔就是看档案的结尾。 head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
head [参数]... [文件]...
参数说明:
- -q 隐藏文件名
- -v 显示文件名
- -c<字节> 显示字节数
- -n<行数> 显示的行数
显示指定行数 [root@master01 ~]# head -n 5 anaconda-ks.cfg #version=DEVEL # System authorization information auth --enableshadow --passalgo=sha512 # Use CDROM installation media cdrom --------------------------------------------- 显示指定字节数 [root@master01 ~]# head -c 8 anaconda-ks.cfg #version[root@master01 ~]# --------------------------------------------- 显示文件名 [root@master01 ~]# head -v anaconda-ks.cfg ==> anaconda-ks.cfg <== #version=DEVEL # System authorization information auth --enableshadow --passalgo=sha512 # Use CDROM installation media cdrom # Use graphical install graphical # Run the Setup Agent on first boot firstboot --enable ignoredisk --only-use=sda --------------------------------------------- 隐藏文件名,默认模式 [root@master01 ~]# head -q anaconda-ks.cfg #version=DEVEL # System authorization information auth --enableshadow --passalgo=sha512 # Use CDROM installation media cdrom # Use graphical install graphical # Run the Setup Agent on first boot firstboot --enable ignoredisk --only-use=sda
3.6 tail¶
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
命令格式:
tail [参数] [文件]
参数:
-
-f 循环读取
-
-q 不显示处理信息
-
-v 显示详细的处理信息
-
-c<数目> 显示的字节数
-
-n<行数> 显示文件的尾部 n 行内容
-
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-
-q, --quiet, --silent 从不输出给出文件名的首部
-
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
动态加载文件内容 [root@master01 src]# tail -f file line1 line2 --------------------------------------------- 显示详细处理信息 [root@master01 src]# tail -v file ==> file <== line1 line2 --------------------------------------------- 显示末尾3行 [root@master01 src]# tail -3f passwd chrony:x:998:996::/var/lib/chrony:/sbin/nologin ntp:x:38:38::/etc/ntp:/sbin/nologin saslauth:x:997:76:Saslauthd user:/run/saslauthd:/sbin/nologin --------------------------------------------- 显示文件 file 的最后 10 个字符 [root@master01 src]# cat file line1 line2 [root@master01 src]# tail -c 4 file ne2
3.7 tailf¶
等价于tail -f,与tail -f不同的事,如果文件不增长,那么它不会访问磁盘文件,也不会更改文件的访问时间。
3.8 cut¶
Linux cut命令用于显示每行从开头算起 num1 到 num2 的文字。
命令格式:
cut [-bn] [file] cut [-c] [file] cut [-df] [file]
使用说明:
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数:
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域。
- -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的 范围之内,该字符将被写出;否则,该字符将被排除
[root@master01 src]# cat info my name is caimengzhi. my age is 32. my hobby hadoop. --------------------------------------------- 按照字节为单位分割, [root@master01 src]# cat info | cut -b 1 m m m [root@master01 src]# cat info | cut -b 1,2 my my my [root@master01 src]# cat info | cut -b 1,2,3 my my my [root@master01 src]# cat info | cut -b 1,2,3,4 my n my a my h [root@master01 src]# cat info | cut -b 1-4 my n my a my h
-c后面接取单个字节,取多个字节使用英文逗号[,]隔开,也支持连续选择,使用英文横岗[-]表示。
以字符为分割单位 [root@master01 src]# cat info | cut -c 1 m m m [root@master01 src]# cat info | cut -c 1,2,3 my my my [root@master01 src]# cat info | cut -c 1,2,3,4 my n my a my h [root@master01 src]# cat info | cut -c 1,2,3,4,5 my na my ag my ho [root@master01 src]# cat info | cut -c 1-5 my na my ag my ho 本选项使用-c 和-d结果没有区别,是因为字母是单个字节字符,要是提前非字母就明显了 [root@master01 src]# cat cmz.txt |cut -b 1-2 i [root@master01 src]# cat cmz.txt 我爱中国. i love china. [root@master01 src]# cat cmz.txt |cut -b 1-2 i [root@master01 src]# cat cmz.txt |cut -c 1-2 我爱 i --------------------------------------------- 自定义分隔符,通常-d,-f搭配使用 [root@master01 src]# cat info my name is caimengzhi. my age is 32. my hobby hadoop. [root@master01 src]# cat info | cut -d " " -f 1 my my my [root@master01 src]# cat info | cut -d " " -f 2 name age hobby [root@master01 src]# cat info | cut -d " " -f 3 is is hadoop.
3.9 split¶
Linux split命令用于将一个文件分割成数个。该指令将大文件分割成较小的文件,在默认情况下将按照每1000行切割成一个小文件。
命令格式:
split [--help][--version][-<行数>][-b <字节>][-C <字节>][-l <行数>][要切割的文件][输出文件名]
参数说明:
- -<行数> : 指定每多少行切成一个小文件
- -b<字节> : 指定每多少字节切成一个小文件
- -d: 使用数字后缀
- -a: 指定后缀长度,默认为2位字母
- -l:指定分割后最大行数
- --help : 在线帮助
- --version : 显示版本信息
- -C<字节> : 与参数"-b"相似,但是在切 割时将尽量维持每行的完整性
- [输出文件名] : 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号
[root@master01 test]# cat ori.txt 1 2 3 4 5 6 7 8 9 10 [root@master01 test]# split -2 ori.txt [root@master01 test]# ll total 24 -rw-r--r-- 1 root root 21 Apr 30 02:22 ori.txt -rw-r--r-- 1 root root 4 Apr 30 02:22 xaa -rw-r--r-- 1 root root 4 Apr 30 02:22 xab -rw-r--r-- 1 root root 4 Apr 30 02:22 xac -rw-r--r-- 1 root root 4 Apr 30 02:22 xad -rw-r--r-- 1 root root 5 Apr 30 02:22 xae [root@master01 test]# cat xaa 1 2 [root@master01 test]# cat xab 3 4 [root@master01 test]# cat xac 5 6 [root@master01 test]# cat xad 7 8 [root@master01 test]# cat xae 9 10 也可以指定名字 [root@master01 test]# split -2 ori.txt cmz_ [root@master01 test]# ll total 24 -rw-r--r-- 1 root root 4 Apr 30 02:24 cmz_aa -rw-r--r-- 1 root root 4 Apr 30 02:24 cmz_ab -rw-r--r-- 1 root root 4 Apr 30 02:24 cmz_ac -rw-r--r-- 1 root root 4 Apr 30 02:24 cmz_ad -rw-r--r-- 1 root root 5 Apr 30 02:24 cmz_ae -rw-r--r-- 1 root root 21 Apr 30 02:22 ori.txt --------------------------------------------- 指定分割最大行数[每个文件] [root@master01 test]# split -l 3 ori.txt c_ [root@master01 test]# ll total 20 -rw-r--r-- 1 root root 6 Apr 30 02:25 c_aa -rw-r--r-- 1 root root 6 Apr 30 02:25 c_ab -rw-r--r-- 1 root root 6 Apr 30 02:25 c_ac -rw-r--r-- 1 root root 3 Apr 30 02:25 c_ad -rw-r--r-- 1 root root 21 Apr 30 02:22 ori.txt [root@master01 test]# cat c_aa 1 2 3 -------------------------------------------- 指定分割大小分割。 [root@master01 test]# cp /sbin/lvm . [root@master01 test]# du -sh lvm 2.2M lvm [root@master01 test]# split -b 500K -d lvm lvm_ [root@master01 test]# ll total 4344 -r-xr-xr-x 1 root root 2220496 Apr 30 02:27 lvm -rw-r--r-- 1 root root 512000 Apr 30 02:27 lvm_00 -rw-r--r-- 1 root root 512000 Apr 30 02:27 lvm_01 -rw-r--r-- 1 root root 512000 Apr 30 02:27 lvm_02 -rw-r--r-- 1 root root 512000 Apr 30 02:27 lvm_03 -rw-r--r-- 1 root root 172496 Apr 30 02:27 lvm_04 [root@master01 test]# du -sh * 2.2M lvm 500K lvm_00 500K lvm_01 500K lvm_02 500K lvm_03 172K lvm_04 --------------------------------------------- 指定输出文件后缀长度 [root@master01 test]# split -b 500K -d lvm lvm_ -a 1 [root@master01 test]# ll total 4344 -r-xr-xr-x 1 root root 2220496 Apr 30 02:27 lvm -rw-r--r-- 1 root root 512000 Apr 30 02:29 lvm_0 -rw-r--r-- 1 root root 512000 Apr 30 02:29 lvm_1 -rw-r--r-- 1 root root 512000 Apr 30 02:29 lvm_2 -rw-r--r-- 1 root root 512000 Apr 30 02:29 lvm_3 -rw-r--r-- 1 root root 172496 Apr 30 02:29 lvm_4
3.10 paste¶
Linux paste命令用于合并文件的列。paste指令会把每个文件以列对列的方式,一列列地加以合并。
命令格式:
paste [-s][-d <间隔字符>][--help][--version][文件...]
参数:
- -d<间隔字符>或--delimiters=<间隔字符> 用指定的间隔字符取代跳格字符。
- -s或--serial 串列进行而非平行处理。
- --help 在线帮助。
- --version 显示帮助信息。
- [文件…] 指定操作的文件路径
[root@master01 test]# cat t1
111
222
333
444
666
[root@master01 test]# cat t2
aaa
bbb
ddd
eee
fff
ggg
[root@master01 test]# paste t1 t2
111 aaa
222 bbb
333
444 ddd
eee
666 fff
ggg
---------------------------------------------
指定链接符号
[root@master01 test]# paste t1 t2 -d :
111:aaa
222:bbb
333:
444:ddd
:eee
666:fff
:ggg
---------------------------------------------
将行转为列
[root@master01 test]# paste -s t1
111 222 333 444 666
[root@master01 test]# paste -s t2
aaa bbb ddd eee fff ggg
[root@master01 test]# paste -s t1 t2
111 222 333 444 666
aaa bbb ddd eee fff ggg
[root@master01 test]# paste -s t1 t2 -d:
111:222:333:444::666
aaa:bbb::ddd:eee:fff:ggg
3.11 sort¶
Linux sort命令用于将文本文件内容加以排序。sort可针对文本文件的内容,以行为单位来排序。
命令格式:
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
参数说明:
- -b 忽略每行前面开始出的空格字符。*
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。*
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。*
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
星号是重点要掌握的
[root@master01 src]# cat info 2 4 3 4 4 1 3 8 ----------------------------------------------------------------------------------------- 按照ASCII码中顺序排序 [root@master01 src]# sort info 1 2 3 3 4 4 4 8 ----------------------------------------------------------------------------------------- 按照数字从小到大排序 [root@master01 src]# sort -n info 1 2 3 3 4 4 4 8 ----------------------------------------------------------------------------------------- 按照数字从大到小排序 [root@master01 src]# sort -nr info 8 4 4 4 3 3 2 1 ----------------------------------------------------------------------------------------- 去重-u [root@master01 src]# sort -u info 1 2 3 4 8 ----------------------------------------------------------------------------------------- [root@master01 src]# cat info1.txt 2 4 4 3 3 4 4 5 4 5 1 1 3 2 8 9 默认是对第一列排序 [root@master01 src]# sort info1.txt 1 1 2 4 3 2 3 4 4 3 4 5 4 5 8 9 ----------------------------------------------------------------------------------------- 指定列排序 [root@master01 src]# cat info1.txt 2 4 4 3 3 4 4 5 4 5 1 1 3 2 8 9 指定第二列排序 [root@master01 src]# sort -t " " -k2 info1.txt 1 1 3 2 4 3 2 4 3 4 4 5 4 5 8 9 第二列排序,同时去重 [root@master01 src]# sort -t " " -k2 -u info1.txt 1 1 3 2 4 3 2 4 4 5 8 9 第二列排序,同时去重,倒序 [root@master01 src]# sort -t " " -k2 -ur info1.txt 8 9 4 5 2 4 4 3 3 2 1 1
3.12 join¶
Linux join命令用于合并文件的列。join指令会把每个文件以列对列的方式,一列列地加以合并。
命令格式:
join [option] [file1] [file2]
参数:
- -a 输出文件中不匹配的行
- -i 忽视大小写
- -1 字段 以第1个文件的指定字段为基础进行合并。
- -2 字段 以第2个文件的指定字段为基础进行合并。
[root@master01 src]# cat a.txt 1 China 2 America 3 Russia [root@master01 src]# cat b.txt 1 Beijing 2 Washington 3 Mosco [root@master01 src]# join a.txt b.txt 1 China Beijing 2 America Washington 3 Russia Mosco
3.13 uniq¶
Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。uniq 可检查文本文件中重复出现的行列。
命令格式:
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件]
参数:
- -c或--count 在每列旁边显示该行重复出现的次数。
- -d或--repeated 仅显示重复出现的行列。
- -f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
- -s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
- -u或--unique 仅显示出一次的行列。
- -w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
- --help 显示帮助。
- --version 显示版本信息。
- [输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
- [输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
[root@master01 src]# cat cmz.txt
cmz 30
cmz 30
cmz 30
Hello 95
Hello 95
Hello 95
Hello 95
Linux 85
Linux 85
name cmz
-----------------------------------------------------------------------------------------
去重
[root@master01 src]# uniq cmz.txt
cmz 30
Hello 95
Linux 85
name cmz
> 去重后,排序
排序
[root@master01 src]# uniq cmz.txt | sort -t ' ' -k2
cmz 30
Linux 85
Hello 95
name cmz
-----------------------------------------------------------------------------------------
去重且显示重复次数
[root@master01 src]# uniq -c cmz.txt
3 cmz 30
4 Hello 95
2 Linux 85
1 name cmz
-----------------------------------------------------------------------------------------
只显示重复行
[root@master01 src]# uniq -d cmz.txt
cmz 30
Hello 95
Linux 85
-----------------------------------------------------------------------------------------
显示没有重复的行
[root@master01 src]# uniq -u cmz.txt
name cmz
3.14 wc¶
Linux wc命令用于计算字数。利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
wc [-clw][--help][--version][文件...]
参数:
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 只显示行数。
- -w或--words 只显示字数。
- --help 在线帮助。
- --version 显示版本信息
[root@master01 src]# cat cmz.txt cmz 30 cmz 30 cmz 30 Hello 95 Hello 95 Hello 95 Hello 95 Linux 85 Linux 85 name cmz [root@master01 src]# wc cmz.txt 10 20 100 cmz.txt | | |__________ 字节数 | |______________ 单词数 |__________________ 行数 [root@master01 src]# wc -l cmz.txt # 行数 10 cmz.txt [root@master01 src]# wc -w cmz.txt # 单词数 20 cmz.txt [root@master01 src]# wc -c cmz.txt # 字节数 100 cmz.txt [root@master01 src]# wc cmz.txt cmz1.txt # 统计两个文件的信息 10 20 100 cmz.txt # 第一个文件行数为10,单词数为20,字节数为100 10 20 100 cmz1.txt # 第二个文件行数为10,单词数为20,字节数为100 20 40 200 total # 两个文件总行数为20,单词总数为40个,字节总数为200个
3.15 iconv¶
linux系统默认编码是utf-8,而windows系统默认是GB2312【国人电脑系统哈】,在windows上编辑的文传到Linux上就有乱码,需要编码转化。很少用。
iconv -f [编码1] -t [编码2] 源文件
参数:
- -f 指定源文件的编码格式
- -t 指定输出文件夹的编码方式
[root@master01 src]# iconv -f gb2312 -t utf-8 cmz.txt cmz 30 cmz 30 cmz 30 Hello 95 Hello 95 Hello 95 Hello 95 Linux 85 Linux 85 name cmz
3.16 dos2unix¶
dos2unix就是把windows文件"\r\n"转成"\n",unix2dos就是反过来把linux上的文件"\n"转成"\r\n"
[root@master01 src]# dos2unix c1.log dos2unix: converting file c1.log to Unix format ...
3.17 diff¶
Linux diff命令用于比较文件的差异。diff以逐行的方式,比较文本文件的异同处。如果指定要比较目录,则diff会比较目录中相同文件名的文件,但不会比较其中子目录。
[root@master01 src]# cat c1.log 1 2 3 [root@master01 src]# cat c2.log 1 3 3 [root@master01 src]# diff c1.log c2.log 2c2 < 2 --- > 3 显示第二行不同,横向上面是第一个文件内容,横向下面是第二个文件内容
3.18 vimdiff¶
Linux vimdiff命令也是用于比较文件的差异,只是会diff更加高级,图形化高亮显示差异。
[root@master01 src]# vimdiff c1.log c2.log 2 files to edit 1 | 1 2 | 3 《--------这行会高亮显示 3 | 3
3.19 rev¶
cat是显示文件夹的命令,这个大家都知道,tac是cat的倒写,意思也和它是相反的。cat是从第一行显示到最后一行,而tac是从最后一行显示到第一行,而rev 则是从最后一个字符显示到第一个字符。
语法
rev [文件]
参数:
- -h 帮助
- -V 版本
[root@master01 cmz]# rev -V rev from util-linux 2.23.2 ----------------------------------------------------------------------------------------- [root@master01 cmz]# rev -h Usage: rev [options] [file ...] Options: -V, --version output version information and exit -h, --help display this help and exit For more information see rev(1). ----------------------------------------------------------------------------------------- [root@master01 cmz]# cat cmz.txt 1 2 3 4 5 6 7 8 9 [root@master01 cmz]# rev cmz.txt 3 2 1 6 5 4 9 8 7
每行的数据从后到前显示。行没变,只是行内元素翻转180度。
3.20 tr¶
Linux tr 命令用于转换或删除文件中的字符。tr 指令从标准输入设备读取数据,经过字符串转译后,将结果输出到标准输出设备。
语法
tr [-cdst][--help][--version][第一字符集][第二字符集] tr [OPTION]…SET1[SET2]
参数说明:
- -c, --complement:反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换
- -d, --delete:删除指令字符
- -s, --squeeze-repeats:缩减连续重复的字符成指定的单个字符
- -t, --truncate-set1:削减 SET1 指定范围,使之与 SET2 设定长度相等
- --help:显示程序用法信息
- --version:显示程序本身的版本信息
- 字符集合的范围:
- \NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符)
- \ 反斜杠
- \a Ctrl-G 铃声
- \b Ctrl-H 退格符
- \f Ctrl-L 走行换页
- \n Ctrl-J 新行
- \r Ctrl-M 回车
- \t Ctrl-I tab键
- \v Ctrl-X 水平制表符
- CHAR1-CHAR2 :字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。
- [CHAR*] :这是 SET2 专用的设定,功能是重复指定的字符到与 SET1 相同长度为止
- [CHAR*REPEAT] :这也是 SET2 专用的设定,功能是重复指定的字符到设定的 REPEAT 次数为止(REPEAT 的数字采 8 进位制计算,以 0 为开始)
- [:alnum:] :所有字母字符与数字
- [:alpha:] :所有字母字符
- [:blank:] :所有水平空格
- [:cntrl:] :所有控制字符
- [:digit:] :所有数字
- [:graph:] :所有可打印的字符(不包含空格符)
- [:lower:] :所有小写字母
- [:print:] :所有可打印的字符(包含空格符)
- [:punct:] :所有标点字符
- [:space:] :所有水平与垂直空格符
- [:upper:] :所有大写字母
- [:xdigit:] :所有 16 进位制的数字
- [=CHAR=] :所有符合指定的字符(等号里的 CHAR,代表你可自订的字符)
[root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr 'my' 'My' < cmz.txt My naMe is caiMengzhi. My hobby is Python. My QQ is 610658552. My site is https://caiMengzhi.github.io/books [root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books
tr 替换比较特殊,后面接文件需要使用<,且tr不会改变原文件内容,且替换原则是,m替换为M,y替换为y,不是将my替换为My
统一大小写 # 1. 小写全部转成大写 [root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr [a-z] [A-Z] < cmz.txt MY NAME IS CAIMENGZHI. MY HOBBY IS PYTHON. MY QQ IS 610658552. MY SITE IS HTTPS://CAIMENGZHI.GITHUB.IO/BOOKS [root@master01 cmz]# tr '[a-z]' '[A-Z]' < cmz.txt MY NAME IS CAIMENGZHI. MY HOBBY IS PYTHON. MY QQ IS 610658552. MY SITE IS HTTPS://CAIMENGZHI.GITHUB.IO/BOOKS [root@master01 cmz]# tr "[a-z]" "[A-Z]" < cmz.txt MY NAME IS CAIMENGZHI. MY HOBBY IS PYTHON. MY QQ IS 610658552. MY SITE IS HTTPS://CAIMENGZHI.GITHUB.IO/BOOKS [root@master01 cmz]# tr [:lower:] [:upper:] < cmz.txt MY NAME IS CAIMENGZHI. MY HOBBY IS PYTHON. MY QQ IS 610658552. MY SITE IS HTTPS://CAIMENGZHI.GITHUB.IO/BOOKS
[a-z]是a到z的所有小写字母,[A-Z]是A到Z的所有大写字母,a替换为A,b替换为B,以此类推z替换为Z。
且加不加单引号,双引号结果都一样。
[root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr '[0-9]' '[a-j]' < cmz.txt my name is caimengzhi. my hobby is Python. my QQ is gbagfiffc. my site is https://caimengzhi.github.io/books
[0-9]表示0到9的所有整数,0替换为a,1替换为b,以此类推,9替换为j。
删除某字符,以下是删除my字符,使用-d表示删除字符 [root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr -d 'my' < cmz.txt nae is caiengzhi. hobb is Pthon. QQ is 610658552. site is https://caiengzhi.github.io/books ---------------------------------------------------------------------------------------- [root@master01 cmz]# tr -d 'myi' < cmz.txt nae s caengzh. hobb s Pthon. QQ s 610658552. ste s https://caengzh.gthub.o/books 删除回车换行和制表符,这样就会变成一行 [root@master01 cmz]# tr -d '\t\n' < cmz.txt my name is caimengzhi.my hobby is Python.my QQ is 610658552.my site is https://caimengzhi.github.io/books
删除
my字符表示凡是文件出现m和y字符都会被删除,而不是单单删除my这个组合字符
删除某些字符 [root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr -d '[1-5]' < cmz.txt # 删除1到5 中任意字符 my name is caimengzhi. my hobby is Python. my QQ is 6068. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr -d '[1-5a-c]' < cmz.txt # 删除1到5中和a到c任意字符 my nme is imengzhi. my hoy is Python. my QQ is 6068. my site is https://imengzhi.githu.io/ooks
取反删除,处理数字保留,其他都删除 [root@master01 cmz]# cat cmz.txt my name is caimengzhi. my hobby is Python. my QQ is 610658552. my site is https://caimengzhi.github.io/books [root@master01 cmz]# tr -c '[0-9]' "*" < cmz.txt ****************************************************610658552************************************************[root@master01 cmz]#
保留连续字符的第一个,其他的删除。 压缩连续字符 [root@master01 cmz]# echo 'cccaaaiiimengzhi' | tr -s 'caimengzhi' caimengzhi
3.21 od¶
Linux od命令用于输出文件内容。od指令会读取所给予的文件的内容,并将其内容以八进制字码呈现出来。
语法
od [-abcdfhilovx][-A <字码基数>][-j <字符数目>][-N <字符数目>][-s <字符串字符数>][-t <输出格式>][-w <每列字符数>][--help][--version][文件...]
参数:
- -a 此参数的效果和同时指定"-ta"参数相同。
- -A<字码基数> 选择要以何种基数计算字码。
- -b 此参数的效果和同时指定"-toC"参数相同。
- -c 此参数的效果和同时指定"-tC"参数相同。
- -d 此参数的效果和同时指定"-tu2"参数相同。
- -f 此参数的效果和同时指定"-tfF"参数相同。
- -h 此参数的效果和同时指定"-tx2"参数相同。
- -i 此参数的效果和同时指定"-td2"参数相同。
- -j<字符数目>或--skip-bytes=<字符数目> 略过设置的字符数目。
- -l 此参数的效果和同时指定"-td4"参数相同。
- -N<字符数目>或--read-bytes=<字符数目> 到设置的字符数目为止。
- -o 此参数的效果和同时指定"-to2"参数相同。
- -s<字符串字符数>或--strings=<字符串字符数> 只显示符合指定的字符数目的字符串。
- -t<输出格式>或--format=<输出格式> 设置输出格式。
- -v或--output-duplicates 输出时不省略重复的数据。
- -w<每列字符数>或--width=<每列字符数> 设置每列的最大字符数。
- -x 此参数的效果和同时指定"-h"参数相同。
- --help 在线帮助。
- --version 显示版本信息。
使用单字节八进制解释进行输出,注意左侧的默认地址格式为八字节: [root@master01 cmz]# echo "1 2 3">cmz.txt [root@master01 cmz]# echo "a b c">>cmz.txt [root@master01 cmz]# cat cmz.txt 1 2 3 a b c [root@master01 cmz]# od -c cmz.txt 0000000 1 2 3 \n a b c \n 0000014 ----------------------------------------------------------------------------------------- 使用ASCII码进行输出,注意其中包括转义字符 97 32 98 32 99 10 0000014 ----------------------------------------------------------------------------------------- 使用单字节十进制进行解释 [root@master01 cmz]# od -A d -c cmz.txt 0000000 1 2 3 \n a b c \n 0000012
实际生产中使用的概率很小。
3.22 tee¶
Linux tee命令用于读取标准输入的数据,并将其内容输出成文件。tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
语法
tee [-ai][--help][--version][文件...]
参数:
- -a或--append 附加到既有文件的后面,而非覆盖它.
- -i或--ignore-interrupts 忽略中断信号。
- --help 在线帮助。
- --version 显示版本信息。
[root@master01 cmz]# touch {1..10}.txt
[root@master01 cmz]# ls
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
[root@master01 cmz]# ls | tee out.txt
10.txt
1.txt
2.txt
3.txt
4.txt
5.txt
6.txt
7.txt
8.txt
9.txt
out.txt
[root@master01 cmz]# ls
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt out.txt
[root@master01 cmz]# cat out.txt
10.txt
1.txt
2.txt
3.txt
4.txt
5.txt
6.txt
7.txt
8.txt
9.txt
out.txt
3.23 vi vim¶
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在。但是目前我们使用比较多的是 vim 编辑器。vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正确性,方便程序设计。
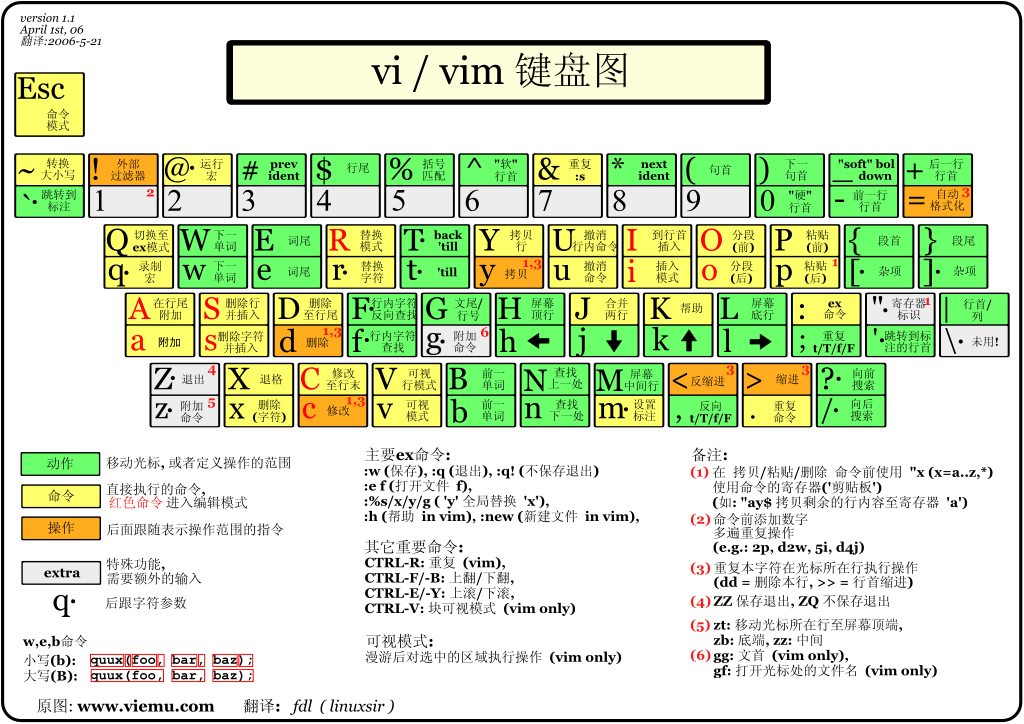
基本上 vi/vim 共分为三种模式,分别是**命令模式(Command mode),**输入模式(Insert mode)**和**底线命令模式(Last line mode)。 这三种模式的作用分别是:
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。
以下是常用的几个命令:
- i 切换到输入模式,以输入字符。
- x 删除当前光标所在处的字符。
- : 切换到底线命令模式,以在最底一行输入命令。
若想要编辑文本:启动Vim,进入了命令模式,按下i,切换到输入模式。
命令模式只有一些最基本的命令,因此仍要依靠底线命令模式输入更多命令。
输入模式
在命令模式下按下i就进入了输入模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合,输入字符
- ENTER,回车键,换行
- BACK SPACE,退格键,删除光标前一个字符
- DEL,删除键,删除光标后一个字符
- 方向键,在文本中移动光标
- HOME/END,移动光标到行首/行尾
- Page Up/Page Down,上/下翻页
- Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
- ESC,退出输入模式,切换到命令模式
底线命令模式
在命令模式下按下:(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
- q 退出程序
- w 保存文件
按ESC键可随时退出底线命令模式。
简单的说,我们可以将这三个模式想成底下的图标来表示:
vim/vi 工作模式
进入 退出[输入:wq或者q或者x]
-------------------| |--------------
vi/vim filename | |
\|/ \|/
|————|——-----———|————|
| command pattern |
|————————————————————|
/ / \ \
输入i/a/o / / ESC : \ \ 命令回车结束运行
/ / \ \
|—————-----————| |-------------------------|
| input pattern| | button line pattern |
|——————————————| |-------------------------|
| 移动光标的方法 | |
|---|---|
| h 或 向左箭头键(←) | 光标向左移动一个字符 |
| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
| l 或 向右箭头键(→) | 光标向右移动一个字符 |
| 如果你将右手放在键盘上的话,你会发现 hjkl 是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! | |
| [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
| [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
| [Ctrl] + [d] | 屏幕『向下』移动半页 |
| [Ctrl] + [u] | 屏幕『向上』移动半页 |
| + | 光标移动到非空格符的下一行 |
| - | 光标移动到非空格符的上一行 |
| n |
那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。例如 20 |
| 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
| $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
| G | 移动到这个档案的最后一行(常用) |
| nG | n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) |
| gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) |
| n |
n 为数字。光标向下移动 n 行(常用) |
| 搜索替换 | |
| /word | 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用) |
| ?word | 向光标之上寻找一个字符串名称为 word 的字符串。 |
| n | 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
| N | 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| 使用 /word 配合 n 及 N 是非常有帮助的!可以让你重复的找到一些你搜寻的关键词! | |
| :n1,n2s/word1/word2/g | n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: 『:100,200s/vbird/VBIRD/g』。(常用) |
| :1,$s/word1/word2/g 或 :%s/word1/word2/g | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用) |
| :1,$s/word1/word2/gc 或 :%s/word1/word2/gc | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) |
| 删除、复制与贴上 | |
| x, X | 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
| nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
| dd | 删除游标所在的那一整行(常用) |
| ndd | n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) |
| d1G | 删除光标所在到第一行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除游标所在处,到该行的最后一个字符 |
| d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
| yy | 复制游标所在的那一行(常用) |
| nyy | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
| y1G | 复制游标所在行到第一行的所有数据 |
| yG | 复制游标所在行到最后一行的所有数据 |
| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
| p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
| J | 将光标所在行与下一行的数据结合成同一行 |
| c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
| u | 复原前一个动作。(常用) |
| [Ctrl]+r | 重做上一个动作。(常用) |
| 这个 u 与 [Ctrl]+r 是很常用的指令!一个是复原,另一个则是重做一次~ 利用这两个功能按键,你的编辑,嘿嘿!很快乐的啦! | |
| . | 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用) |
第二部份:一般模式切换到编辑模式的可用的按钮说明
| 进入输入或取代的编辑模式 | |
|---|---|
| i, I | 进入输入模式(Insert mode): i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。 (常用) |
| a, A | 进入输入模式(Insert mode): a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。(常用) |
| o, O | 进入输入模式(Insert mode): 这是英文字母 o 的大小写。o 为『在目前光标所在的下一行处输入新的一行』; O 为在目前光标所在处的上一行输入新的一行!(常用) |
| r, R | 进入取代模式(Replace mode): r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止;(常用) |
| 上面这些按键中,在 vi 画面的左下角处会出现『--INSERT--』或『--REPLACE--』的字样。 由名称就知道该动作了吧!!特别注意的是,我们上面也提过了,你想要在档案里面输入字符时, 一定要在左下角处看到 INSERT 或 REPLACE 才能输入喔! | |
| [Esc] | 退出编辑模式,回到一般模式中(常用) |
第三部份:一般模式切换到指令行模式的可用的按钮说明
| 指令行的储存、离开等指令 | |
|---|---|
| :w | 将编辑的数据写入硬盘档案中(常用) |
| :w! | 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! |
| :q | 离开 vi (常用) |
| :q! | 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 |
| 注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ | |
| :wq | 储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
| ZZ | 这是大写的 Z 喔!若档案没有更动,则不储存离开,若档案已经被更动过,则储存后离开! |
| :w [filename] | 将编辑的数据储存成另一个档案(类似另存新档) |
| :r [filename] | 在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 |
| :n1,n2 w [filename] | 将 n1 到 n2 的内容储存成 filename 这个档案。 |
| :! command | 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! |
| vim 环境的变更 | |
| :set nu | 显示行号,设定之后,会在每一行的前缀显示该行的行号 |
| :set nonu | 与 set nu 相反,为取消行号! |
特别注意,在 vi/vim 中,数字是很有意义的!数字通常代表重复做几次的意思! 也有可能是代表去到第几个什么什么的意思。
举例来说,要删除 50 行,则是用 『50dd』 对吧! 数字加在动作之前,如我要向下移动 20 行呢?那就是『20j』或者是『20↓』即可。